
En la pantalla de una computadora, la foto borrosa de una bandera comienza a enfocarse. Surgen arrugas en su superficie, pliegues que ondean en un viento fantasmal. Al acercar la imagen de nuevo, empiezan a aparecer hilos. De nuevo, y hay un indicio de deshilachado en el borde. En este juego de manos digital, no estás viendo píxeles simplemente estirarse o mancharse. Estás viendo cómo la inteligencia artificial recrea lo que una cámara mejor podría haber visto.
Esta es la promesa de Chain-of-Zoom, o CoZ, un nuevo marco de IA desarrollado por investigadores surcoreanos de KAIST AI, dirigidos por Kim Jaechul. Este enfoque busca resolver uno de los problemas más complejos de la mejora de imagen moderna: cómo ampliar drásticamente una imagen de baja resolución manteniendo los detalles nítidos y creíbles.
Aparentemente, la mejor forma de hacerlo es no hacer zoom en todo de una vez.
Hazte a un lado, CSI
Los sistemas tradicionales de superresolución de imagen única (SISR) se esfuerzan al máximo para adivinar qué falta cuando se les pide que aumenten la escala de una imagen. Muchos se basan en modelos generativos entrenados para crear versiones plausibles de alta resolución a partir de fotos de baja resolución. Es como una especie de conjetura fundamentada que rellena el espacio vacío con píxeles con alta probabilidad de estar ahí, en términos probabilísticos. Pero estos modelos sólo son eficaces en la medida en que su entrenamiento les permite, y tienden a fallar cuando se les exige más allá de los límites habituales.
“Los modelos de última generación se destacan en sus factores de escala entrenados, pero fallan cuando se les pide que amplíen las imágenes mucho más allá de ese rango”, escribe el equipo de KAIST en su artículo que apareció en el servidor de preimpresión arXiv.
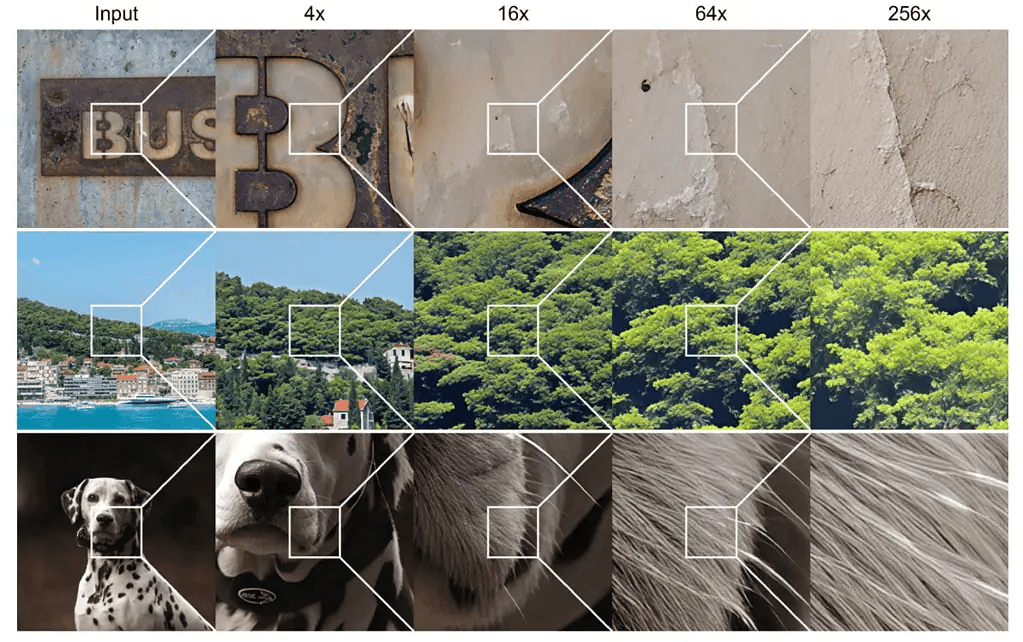
Chain-of-Zoom supera esta limitación al dividir el proceso de zoom en pasos manejables. En lugar de ampliar una imagen 256 veces de una sola vez (un salto que haría que la IA difuminara o alucinara detalles), CoZ construye una escalera. Cada paso es un pequeño zoom calculado, basado en el anterior.
En cada etapa de esta escalera, CoZ utiliza un modelo de superresolución existente, como un modelo de difusión bien entrenado, para refinar la imagen. Pero no se detiene ahí. Un Modelo de Visión-Lenguaje (VLM) se une al proceso, generando indicaciones descriptivas que ayudan a la IA a imaginar lo que debería aparecer en la siguiente versión de mayor resolución.
La segunda imagen es un acercamiento de la primera. Con base en este conocimiento, ¿qué hay en la segunda imagen? Esa es una de las indicaciones utilizadas durante el entrenamiento. La función del VLM es responder con unas pocas palabras significativas: “nervaduras de las hojas”, “textura del pelaje”, “pared de ladrillos”, etc. Estas indicaciones guían el siguiente paso de acercamiento, como indicaciones verbales que se le dan a un artista que dibuja con más detalle.
Entre píxeles y palabras
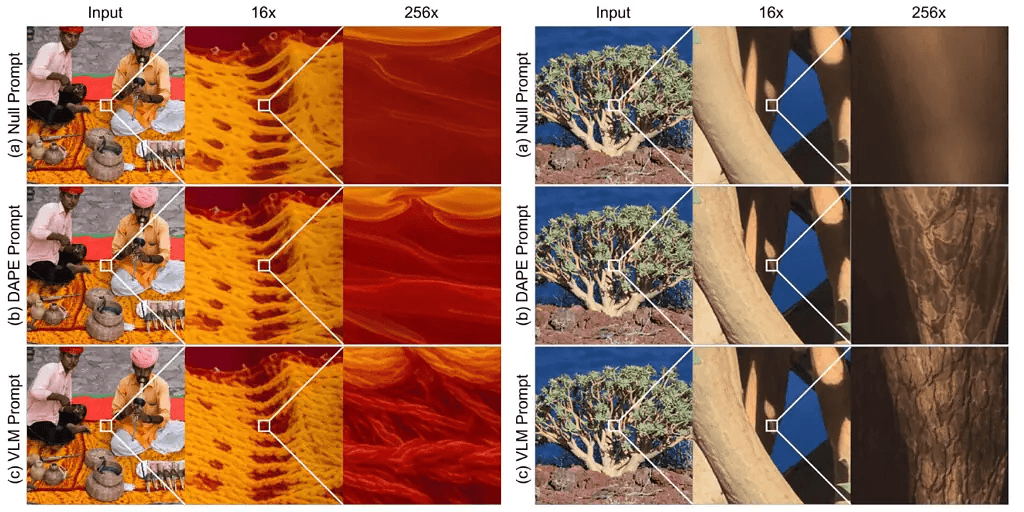
Esta interacción entre imágenes y lenguaje es lo que distingue a CoZ. A medida que se amplía la imagen, esta pierde fidelidad: las pistas visuales se desvanecen y el contexto desaparece. Ahí es cuando las palabras cobran mayor importancia.
Pero generar las indicaciones correctas no es fácil. Los VLM estándar pueden repetirse, inventar frases extrañas o malinterpretar información confusa. Para mantener el proceso sólido y eficiente, los investigadores recurrieron al aprendizaje por refuerzo con retroalimentación humana (RLHF). Entrenaron su modelo de generación de indicaciones para que se ajustara a las preferencias humanas mediante una técnica llamada Optimización Generalizada de la Política de Recompensas (GRPO).
Tres tipos de retroalimentación guiaron el proceso de aprendizaje:
- Un crítico de VLM evaluó las indicaciones según lo bien que coincidían con las imágenes.
- Una lista negra penaliza frases confusas como “primera imagen” o “segunda imagen”.
- Un filtro de repetición desaconseja el texto genérico o repetitivo.
A medida que avanzaba el entrenamiento, las indicaciones se volvieron más claras, específicas y útiles. Palabras como “pinza de cangrejo” reemplazaron conjeturas vagas como “pata de hormiga”. El modelo final guió consistentemente al motor de superresolución hacia imágenes detalladas y creíbles, incluso con un zoom de 256 aumentos.
Potencial del mundo real

En comparaciones directas con otros métodos, como el aumento de escala por vecino más cercano y la superresolución de un paso, CoZ produjo imágenes que destacaron por su claridad y textura. Sus resultados se evaluaron utilizando diversas métricas de calidad sin referencia, como NIQE y CLIPIQA. En cuatro niveles de aumento (4×, 16×, 64× y 256×), CoZ superó consistentemente a las alternativas, especialmente a escalas más altas. Pero más allá de los números, la promesa de Chain-of-Zoom radica en su flexibilidad.

No requiere reentrenar el modelo de superresolución subyacente. Esto lo hace más accesible para desarrolladores e investigadores que ya utilizan modelos como Difusión Estable. También facilita el acceso a aplicaciones que requieren un zoom rápido y de alta fidelidad sin un alto coste computacional.
Todo esto puede transformar el modo en que abordamos la superresolución.
Los usos potenciales abarcan diversos campos, incluidos:
- Imágenes médicas, en las que un mayor nivel de detalle podría ayudar al diagnóstico.
- Imágenes de vigilancia que ayudan a los investigadores a leer matrículas lejanas o rasgos faciales.
- Preservación cultural, restauración de fotografías antiguas con una claridad sin precedentes.
- Visualización científica, especialmente en campos como la microscopía o la astronomía.
En una demostración, CoZ mejoró la foto de una hoja hasta que se hicieron visibles las venas individuales, características que no eran perceptibles en la imagen original de baja resolución. En otra, reveló la fina trama de un textil.
Si bien estos ejemplos son convincentes, también sugieren un arma de doble filo. Al ampliar lo suficiente, ya no se ve la imagen original, sino una copia sintética. En otras palabras, el paisaje de la imagen mejorada no existe en la realidad, aunque pueda parecerse mucho al sujeto original de la foto. Esto no hace que este modelo sea menos útil, pero es necesario comprender perfectamente estas limitaciones.
Las limitaciones conllevan riesgos asociados. Tecnologías como Chain-of-Zoom, si bien no son engañosas por naturaleza, podrían utilizarse para manipular datos visuales o generar contenido engañoso a partir de fuentes borrosas.
Los autores lo reconocen en su artículo: “La generación de alta fidelidad a partir de entradas de baja resolución puede generar preocupación con respecto a la desinformación o la reconstrucción no autorizada de datos visuales sensibles”.
En un mundo que ya lidia con los deepfakes y la desinformación visual, la capacidad de “ver más” no siempre es una ventaja. La solución, como siempre, reside en un desarrollo transparente y un uso responsable.
Una nueva perspectiva sobre la visión
Por ahora, Chain-of-Zoom representa una solución elegante a un problema profundamente práctico. No reinventa la rueda, simplemente cambia su funcionamiento.
En lugar de estirar las imágenes más allá de su punto de ruptura, CoZ pregunta: ¿qué pasa si lo hacemos con calma, un zoom a la vez?
El resultado no son solo imágenes más nítidas. Es un camino más claro hacia adelante.
Fuente: ZME Science.
