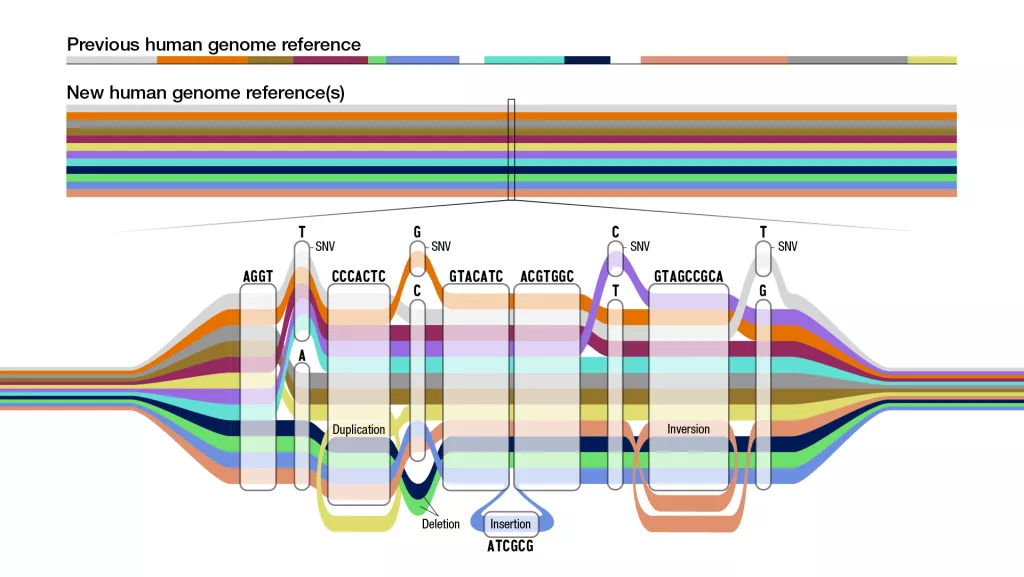
Los científicos han publicado el primer “pangenoma” humano: una secuencia genética completa que incorpora genomas no solo de un individuo, sino de 47. Estos 47 individuos provienen de todo el mundo y, por lo tanto, aumentan enormemente la diversidad de los genomas representados en la secuencia, en comparación con la secuencia anterior del genoma humano completo que los científicos utilizan como referencia para el estudio. La primera secuencia del genoma humano se publicó con algunas lagunas en 2003 y solo se hizo “sin lagunas” en 2022. Si ese primer genoma humano es una cadena lineal simple de código genético, el nuevo pangenoma es una serie de caminos ramificados.
El objetivo final del Human Pangenome Reference Consortium, que publicó el primer borrador del pangenoma el miércoles 10 de mayo en la revista Nature, es secuenciar al menos 350 individuos de diferentes poblaciones de todo el mundo. Aunque el 99,9% del genoma es el mismo de una persona a otra, hay mucha diversidad en ese 0,1% final.
“En lugar de usar una sola secuencia del genoma como nuestro sistema de coordenadas, deberíamos tener una representación basada en los genomas de muchas personas diferentes para que podamos capturar mejor la diversidad genética en los humanos”, dijo Melissa Gymrek, investigadora de genética de la Universidad de California, San Diego, que no participó en el proyecto, a Live Science.
Una referencia para la salud
La primera secuencia completa del genoma humano fue completada en 2003 por el Proyecto Genoma Humano y se basó en el ADN de una persona. Más tarde, se agregaron fragmentos de otros 20 individuos, pero el 70% de la secuencia que usan los científicos para comparar la variación genética aún proviene de una sola persona.
Los genetistas usan el genoma de referencia como guía cuando secuencian partes de los códigos genéticos de las personas, dijo a Live Science Arya Massarat, estudiante de doctorado en el laboratorio de Gymrek y coautora de un editorial sobre la nueva investigación en la revista Nature. Hacen coincidir los fragmentos de ADN recién decodificados con la referencia para descubrir cómo encajan dentro del genoma en su conjunto. También usan el genoma de referencia como estándar para identificar variaciones genéticas (versiones diferentes de genes que difieren de la referencia) que podrían estar relacionadas con condiciones de salud. Pero con una sola referencia, en su mayoría de una persona, los científicos solo tienen una ventana limitada de diversidad genética para estudiar.
El primer borrador del pangenoma ahora duplica la cantidad de grandes variantes del genoma, conocidas como variantes estructurales, que los científicos pueden detectar, llevándolas a 18,000. Estos son lugares en el genoma donde se han eliminado, insertado o reorganizado grandes fragmentos. El nuevo borrador también agrega 119 millones de nuevos pares de bases, es decir, las “letras” emparejadas que forman la secuencia de ADN, y 1.115 nuevas mutaciones de duplicación de genes a la versión anterior del genoma humano.
“Realmente es comprender y catalogar estas diferencias entre los genomas lo que nos permite comprender cómo operan las células y su biología y cómo funcionan, además de comprender las diferencias genéticas y cómo contribuyen a comprender las enfermedades humanas”, dijo la coautora del estudio, Karen Miga, dijo un genetista de la Universidad de California, Santa Cruz, en una conferencia de prensa celebrada el 9 de mayo. El pangenoma podría ayudar a los científicos a comprender mejor las condiciones complejas en las que los genes desempeñan un papel influyente, como el autismo, la esquizofrenia, los trastornos inmunitarios y las enfermedades coronarias cardiacas, dijeron los investigadores involucrados en el estudio en la conferencia de prensa.
Por ejemplo, se sabe que el gen de la lipoproteína A es uno de los mayores factores de riesgo de enfermedad coronaria en los afroamericanos, pero los cambios genéticos específicos involucrados son complejos y poco conocidos, dijo el coautor del estudio Evan Eichler, investigador de genómica en la Universidad de Washington en Seattle, a los periodistas. Con el pangenoma, los investigadores ahora pueden comparar más a fondo la variación en personas con enfermedades cardíacas y sin ellas, y esto podría ayudar a aclarar el riesgo de enfermedades cardíacas de las personas en función de las variantes del gen que portan.
Una comprensión diversa
El borrador actual del pangenoma utilizó datos de los participantes en el Proyecto 1000 Genomas, que fue el primer intento de secuenciar genomas de un gran número de personas de todo el mundo. Los participantes incluidos acordaron que sus secuencias genéticas fueran anonimizadas e incluidas en bases de datos disponibles públicamente.
El nuevo estudio también usó tecnología de secuenciación avanzada llamada “secuenciación de lectura larga”, a diferencia de la secuenciación de lectura corta que se presentó antes. La secuenciación de lectura corta es lo que sucede cuando envías tu ADN a una empresa como 23andMe, dijo Eichler. Los investigadores leen pequeños segmentos de ADN y luego los unen en un todo. Este tipo de secuenciación puede capturar una cantidad decente de variación genética, pero puede haber poca superposición entre cada fragmento de ADN. La secuenciación de lectura larga, por otro lado, captura grandes segmentos de ADN a la vez.
Si bien es posible secuenciar un genoma con secuenciación de lectura corta por alrededor de $500, la secuenciación de lectura larga sigue siendo costosa y cuesta alrededor de $10,000 por genoma, dijo Eichler. Sin embargo, el precio está bajando y el equipo del pangenoma espera secuenciar sus próximos lotes de genomas a la mitad de ese costo o menos.
Los investigadores están trabajando para reclutar nuevos participantes para continuar llenando los vacíos de diversidad en el pangenoma, dijo el coautor del estudio Eimear Kenny, profesor de medicina y genética en el Instituto de Salud Genómica de la Escuela de Medicina Icahn en Mount Sinai en la ciudad de Nueva York, a los periodistas. Debido a que la información genética es sensible y debido a que las diferentes reglas rigen el intercambio de datos y la privacidad en diferentes países, este es un trabajo delicado. Los problemas incluyen privacidad, consentimiento informado y la posibilidad de discriminación basada en información genética, dijo Kenny.
Los investigadores ya están descubriendo nuevos procesos genéticos con el borrador del pangenoma. En dos artículos publicados en Nature junto con el trabajo, los investigadores observaron segmentos altamente repetitivos del genoma. Estos segmentos han sido tradicionalmente difíciles de estudiar, dijo a Live Science el bioquímico Brian McStay de la Universidad Nacional de Irlanda Galway, porque secuenciarlos a través de tecnología de lectura corta hace que sea difícil entender cómo encajan entre sí. La tecnología de lectura larga permite leer a la vez fragmentos largos de estas secuencias repetitivas.
Los estudios encontraron que en un tipo de secuencia repetitiva, conocida como duplicaciones segmentarias, hay una cantidad de variación mayor a la esperada, lo que podría ser un mecanismo para la evolución a largo plazo de nuevas funciones para los genes. Sin embargo, en otro tipo de secuencia repetitiva que es responsable de construir las máquinas celulares que crean nuevas proteínas, el genoma se mantiene notablemente estable. El pangenoma permitió a los investigadores descubrir un mecanismo potencial de cómo estos segmentos clave de ADN se mantienen constantes a lo largo del tiempo.
“Esto es solo el comienzo”, dijo McStay. “Habrá una gran cantidad de nueva biología que surgirá de esto”.
Fuente: Live Science.