La inteligencia artificial se está volviendo cada vez más inteligente, y cada vez más humana. Muchas cosas han cambiado en el ajedrez moderno en comparación con el pasado, pero el cambio más importante es la hegemonía de las computadoras. Tomemos a Magnus Carlsen, quien, durante la última década, ha sido el campeón mundial indiscutible de ajedrez, realmente no puede pretender ser el mejor jugador de ajedrez, solo el mejor jugador humano.
Los algoritmos de ajedrez han superado durante mucho tiempo la capacidad humana para jugar el juego, por una razón muy simple: pueden memorizar y calcular tareas simples mucho mejor que nosotros. Pero cuando las IA empezaron a entrar en escena, los algoritmos de ajedrez también iban a revolucionar.
Tradicionalmente, los algoritmos de ajedrez se entrenaron de una manera muy sencilla: se les enseñaron las reglas del juego, se les alimentó con una enorme base de datos de juegos, se les enseñó a calcular y se pusieron en marcha. Pero AlphaZero de Google, por ejemplo, adopta un enfoque muy diferente: se puede decir que AlphaZero se ha convertido, posiblemente, en la mejor entidad de ajedrez del mundo sin estudiar un solo juego humano. En cambio, solo se le enseñaron las reglas del juego y se le permitió jugar contra sí mismo una y otra vez. Curiosamente, esto no solo le permitió lograr una destreza notable, sino también desarrollar un estilo propio. A diferencia de los algoritmos tradicionales que practican juegos muy concretos y exigentes, AlphaZero tiende a jugar de una manera muy conceptual y creativa (aunque la palabra “creativo” seguramente molestará a algunos lectores). Por ejemplo, AlphaZero a menudo sacrificaría una pieza sin una recompensa inmediata a la vista; no necesariamente calcula todos los resultados. En lugar de jugar movimientos que puede calcular completamente para ser mejores, que es lo que hacen la mayoría de los algoritmos, AlphaZero juega movimientos que parecen mejores. Es una forma sorprendentemente humana de abordar el juego, aunque muchos de los movimientos de AlphaZero parecen claramente inhumanos. Ahora, los investigadores de Google han llevado las cosas al siguiente nivel con MuZero.
A diferencia de AlphaZero, a MuZero ni siquiera se le dijeron las reglas del ajedrez. No se le permitió hacer ningún movimiento ilegal, pero se le permitió reflexionar sobre ellos. Esto permite que el algoritmo piense de una manera más humana, considerando las amenazas y posibilidades incluso cuando no sean aparentes o posibles en un momento dado. Por ejemplo, la amenaza de perder una pieza expuesta siempre puede estar presente en el fondo de la mente de un jugador humano, aunque no esté amenazada en este momento. Los investigadores dicen que esto también le permite a MuZero desarrollar una intuición interna con respecto a las reglas del juego.
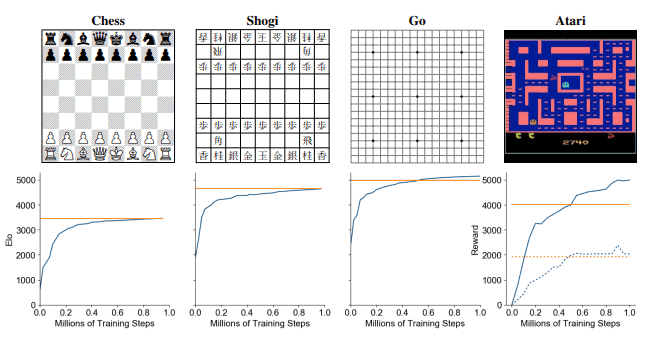
Esto condujo a actuaciones notablemente buenas. Aunque los detalles que presentaron los investigadores son escasos, afirman que MuZero logró el mismo rendimiento que AlphaZero. Pero se pone aún mejor. Los investigadores no solo entrenaron el motor en ajedrez, también lo entrenaron en go, shogi y 57 juegos de Atari que se usan comúnmente en este tipo de estudio.
Los resultados más impresionantes vinieron de Go, un juego que es increíblemente más complejo que el ajedrez. MuZero superó ligeramente el rendimiento de AlphaZero a pesar de usar menos cálculos generales, lo que parece indicar que MuZero tiene una comprensión más profunda del juego y las posiciones en las que estaba jugando. Se informaron actuaciones similares en los juegos de Atari, donde MuZero superó a los motores de última generación en 42 de 57 juegos.
Por supuesto, hay mucho más en esto que solo ajedrez, Go o PacMan. Hay lecciones muy concretas que se pueden aplicar en inteligencia artificial en un entorno muy práctico.
“Muchos de los avances en inteligencia artificial se han basado en una planificación de alto rendimiento”, escribieron los investigadores. “En este artículo presentamos un método que combina los beneficios de ambos enfoques. Nuestro algoritmo, MuZero, ha igualado el rendimiento sobrehumano de los algoritmos de planificación de alto rendimiento en sus dominios favoritos (juegos de mesa lógicamente complejos como el ajedrez y el Go) y ha superado a los algoritmos de [aprendizaje por refuerzo] sin modelos de última generación en sus dominios favoritos: juegos de Atari visualmente complejos”.
Fuente: ZME Science.
