Por: Nicholas Card
Las interfaces cerebro-ordenador son una tecnología revolucionaria que puede ayudar a las personas paralizadas a recuperar funciones que han perdido, como mover una mano. Estos dispositivos registran las señales del cerebro y descifran la acción que el usuario pretende realizar, evitando los nervios dañados o degradados que normalmente transmitirían esas señales cerebrales para controlar los músculos.
Desde 2006, las demostraciones de interfaces cerebro-ordenador en humanos se han centrado principalmente en restaurar los movimientos de los brazos y las manos al permitir que las personas controlen cursores de ordenador o brazos robóticos. Recientemente, los investigadores han comenzado a desarrollar interfaces cerebro-ordenador de voz para restablecer la comunicación de las personas que no pueden hablar.
Cuando el usuario intenta hablar, estas interfaces cerebro-ordenador registran las señales cerebrales únicas de la persona asociadas con los movimientos musculares intentados para hablar y luego las traducen en palabras. Estas palabras pueden luego mostrarse como texto en una pantalla o pronunciarse en voz alta mediante un software de texto a voz.
Soy investigador en el Laboratorio de Neuroprótesis de la Universidad de California, Davis, que forma parte del ensayo clínico BrainGate2. Mis colegas y yo demostramos recientemente una interfaz cerebro-computadora de habla que descifra el intento de habla de un hombre con ELA, o esclerosis lateral amiotrófica, también conocida como enfermedad de Lou Gehrig. La interfaz convierte las señales neuronales en texto con una precisión de más del 97%. La clave de nuestro sistema es un conjunto de modelos de lenguaje de inteligencia artificial: redes neuronales artificiales que ayudan a interpretar las naturales.
Registro de señales cerebrales
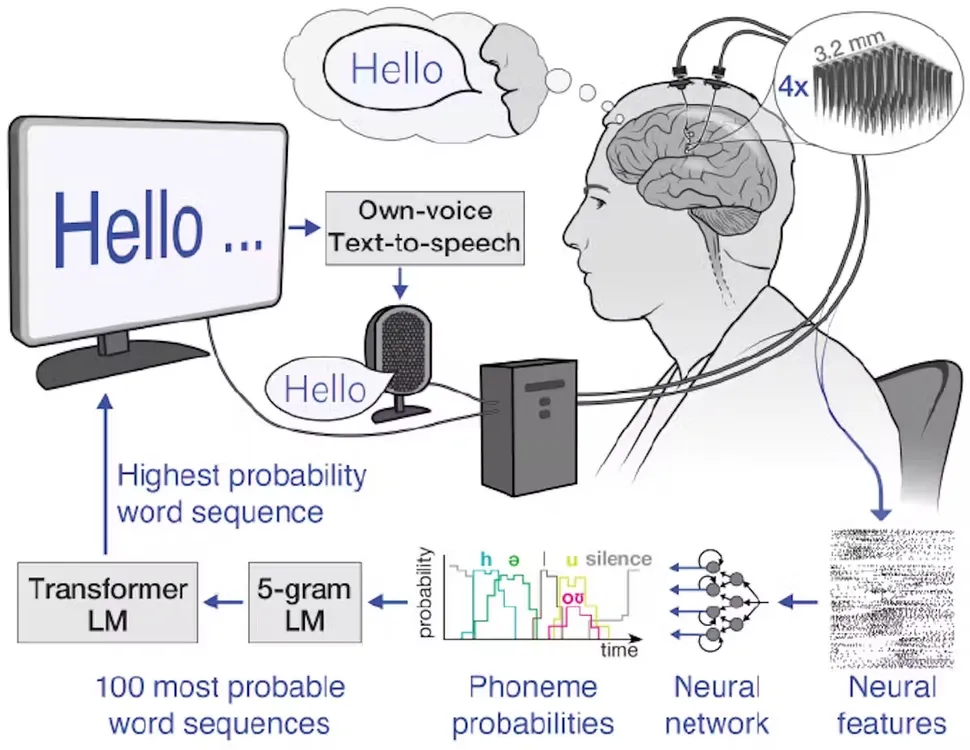
El primer paso en nuestra interfaz cerebro-computadora de habla es registrar las señales cerebrales. Existen varias fuentes de señales cerebrales, algunas de las cuales requieren cirugía para registrarse. Los dispositivos de grabación implantados quirúrgicamente pueden capturar señales cerebrales de alta calidad porque se colocan más cerca de las neuronas, lo que da como resultado señales más fuertes con menos interferencias. Estos dispositivos de grabación neuronal incluyen rejillas de electrodos colocados en la superficie del cerebro o electrodos implantados directamente en el tejido cerebral.
En nuestro estudio, utilizamos conjuntos de electrodos colocados quirúrgicamente en la corteza motora del habla, la parte del cerebro que controla los músculos relacionados con el habla, del participante, Casey Harrell. Registramos la actividad neuronal de 256 electrodos mientras Harrell intentaba hablar.

Descifrar las señales cerebrales
El siguiente desafío es relacionar las complejas señales cerebrales con las palabras que el usuario está tratando de decir. Un enfoque es mapear los patrones de actividad neuronal directamente con las palabras habladas. Este método requiere registrar las señales cerebrales correspondientes a cada palabra varias veces para identificar la relación promedio entre la actividad neuronal y palabras específicas. Si bien esta estrategia funciona bien para vocabularios pequeños, como se demostró en un estudio de 2021 con un vocabulario de 50 palabras, se vuelve poco práctica para vocabularios más grandes. Imagina pedirle al usuario de la interfaz cerebro-computadora que intente decir todas las palabras del diccionario varias veces: podría llevar meses y aún así no funcionaría con palabras nuevas.
En cambio, utilizamos una estrategia alternativa: mapear las señales cerebrales con los fonemas, las unidades básicas de sonido que forman las palabras. En inglés, hay 39 fonemas, incluidos ch, er, oo, pl y sh, que se pueden combinar para formar cualquier palabra. Podemos medir la actividad neuronal asociada a cada fonema varias veces con solo pedirle al participante que lea algunas oraciones en voz alta. Al asignar con precisión la actividad neuronal a los fonemas, podemos unirlos en cualquier palabra en inglés, incluso aquellas con las que el sistema no fue entrenado explícitamente.
Para asignar señales cerebrales a fonemas, utilizamos modelos avanzados de aprendizaje automático. Estos modelos son particularmente adecuados para esta tarea debido a su capacidad para encontrar patrones en grandes cantidades de datos complejos que serían imposibles de discernir para los humanos. Piensa en estos modelos como oyentes superinteligentes que pueden distinguir información importante de señales cerebrales ruidosas, de manera similar a como tú podrías concentrarte en una conversación en una habitación llena de gente. Usando estos modelos, pudimos descifrar secuencias de fonemas durante un intento de habla con más del 90% de precisión.
De fonemas a palabras
Una vez que tenemos las secuencias de fonemas descifradas, necesitamos convertirlas en palabras y oraciones. Esto es un desafío, especialmente si la secuencia de fonemas descifrada no es perfectamente precisa. Para resolver este rompecabezas, utilizamos dos tipos complementarios de modelos de lenguaje de aprendizaje automático.
El primero son los modelos de lenguaje de n-gramas, que predicen qué palabra es más probable que siga a un conjunto de n palabras. Entrenamos un modelo de lenguaje de 5-gramas, o cinco palabras, en millones de oraciones para predecir la probabilidad de una palabra en función de las cuatro palabras anteriores, capturando el contexto local y las frases comunes. Por ejemplo, después de “soy muy bueno”, podría sugerir “hoy” como más probable que “patata”. Usando este modelo, convertimos nuestras secuencias de fonemas en las 100 secuencias de palabras más probables, cada una con una probabilidad asociada.
El segundo son los modelos de lenguaje grandes, que impulsan los chatbots de IA y también predicen qué palabras son más probables que sigan a otras. Usamos modelos de lenguaje grandes para refinar nuestras elecciones. Estos modelos, entrenados con grandes cantidades de textos diversos, tienen una comprensión más amplia de la estructura y el significado del lenguaje. Nos ayudan a determinar cuál de nuestras 100 oraciones candidatas tiene más sentido en un contexto más amplio.
Al equilibrar cuidadosamente las probabilidades del modelo de n-gramas, el modelo de lenguaje amplio y nuestras predicciones iniciales de fonemas, podemos hacer una suposición muy bien fundamentada sobre lo que el usuario de la interfaz cerebro-computadora está tratando de decir. Este proceso de varios pasos nos permite manejar las incertidumbres en la decodificación de fonemas y producir oraciones coherentes y apropiadas para el contexto.
Beneficios en el mundo real
En la práctica, esta estrategia de decodificación del habla ha tenido un éxito notable. Hemos permitido que Casey Harrell, un hombre con ELA, “hable” con más del 97% de precisión utilizando únicamente sus pensamientos. Este avance le permite conversar fácilmente con su familia y amigos por primera vez en años, todo en la comodidad de su propio hogar.
Las interfaces de voz cerebro-computadora representan un avance significativo en la restauración de la comunicación. A medida que continuamos perfeccionando estos dispositivos, prometen dar voz a quienes han perdido la capacidad de hablar, reconectándolos con sus seres queridos y el mundo que los rodea.
Sin embargo, aún quedan desafíos, como hacer que la tecnología sea más accesible, portátil y duradera a lo largo de los años de uso. A pesar de estos obstáculos, las interfaces de voz cerebro-computadora son un poderoso ejemplo de cómo la ciencia y la tecnología pueden unirse para resolver problemas complejos y mejorar drásticamente la vida de las personas.
Este artículo es una traducción de otro publicado en The Conversation. Puedes leer el texto original haciendo clic aquí.